
超算中心当前运行中的两套系统(系统平台):曙光TC4600百万亿次超级计算系统、瀚海20超级计算系统,均以CPU计算节点为主且存储磁盘空间较小,随着中心用户的持续增加,以及近几年生命科学、材料科学、力学、AI等学科科研程序在GPU上的快速进步发展,现有系统已无法满足校内师生的计算需求。
因此,超算中心通过充分调研并招标采购了一套以GPU计算节点和大容量存储为主的融合计算系统,命名为:瀚海22超级计算系统。经过暑期加班加点赶进度,于8月底完成安装调试,通过2个月的测试运行,2022年11月17日正式完成专家组验收,现面向校内师生用户开放使用。该系统主要配置如下:
节点 | 单节点主要配置 | 主要用途 |
admin22-01 admin22-02 | 2颗Intel Xeon 8358 CPU,共64核,256GB内存,100Gbps IB高速网络 | 系统管理节点,管理员配置与管理系统主要功能等。 |
hanhai22-01 hanhai22-02 | 2颗Intel Xeon 8358 CPU,共64核,256GB内存,100Gbps IB高速网络 | 用户登录节点,编辑文件、提交作业、上传下载数据等。 |
hanhai22-03 | 2颗Intel Xeon 8358 CPU,共64核,512GB内存,100Gbps IB高速网络,2块NVIDIA A6000 40GB显存GPU卡 | 可视化节点,计算数据可视化处理,程序客户端界面运行等。 |
大容量存储 | /gpfs目录,12PB可用存储空间。 | 用户账号目录,数据文件等的存储空间,共享到全部节点挂载使用。 |
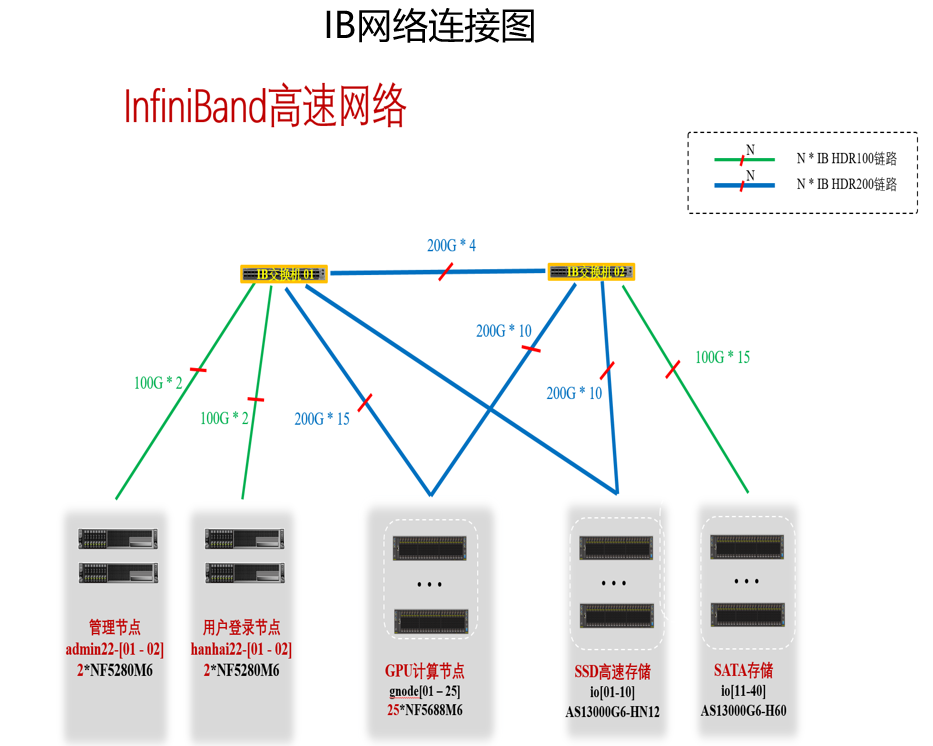
gnode01-gnode25 | 2颗Intel Xeon 8358 CPU,共64核,1TB 内存,3.84TB NVMe硬盘,200Gbps IB高速网络,8块NVIDIA A100 NVLink 80GB显存 GPU卡 | 计算节点,运行作业调度系统分配后的用户程序任务。 |
高速网络 | 200Gbps/100Gbps IB | 存储挂载、节点间通信的高速网络。 |
该系统有如下几个特点:
GPU算力强:25个GPU计算节点,各节点配置8张NVIDIA A100 Tensor Core GPU(单卡80GB显存、峰值性能:9.7TFlops@FP64、19.5TFlops@FP64 Tensor Core、节点内GPU卡间600GB/s NVLink高速互联),实测单节点FP64 Tensor Core:性能超过100PFlops。共200张GPU卡,GPU峰值计算能力高达:1.94PFlops@FP64、3.84PFlops@FP64 Tensor Core,国内高校中的顶配。
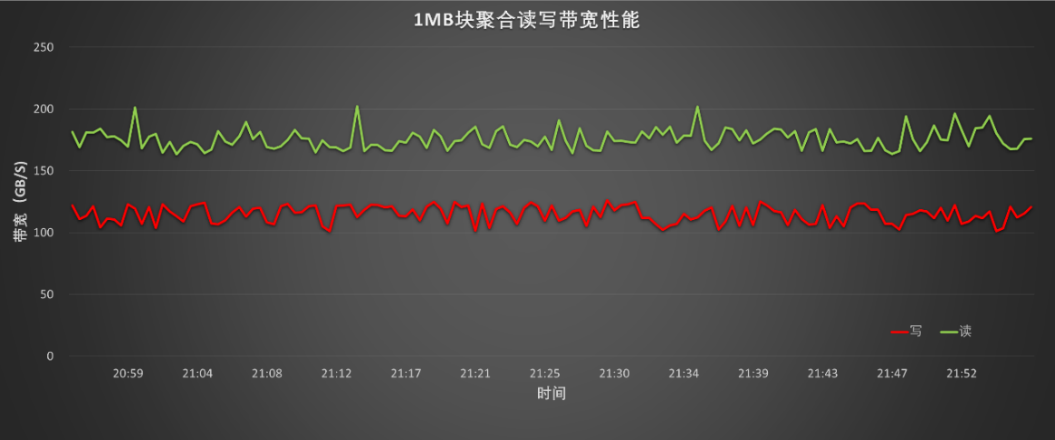
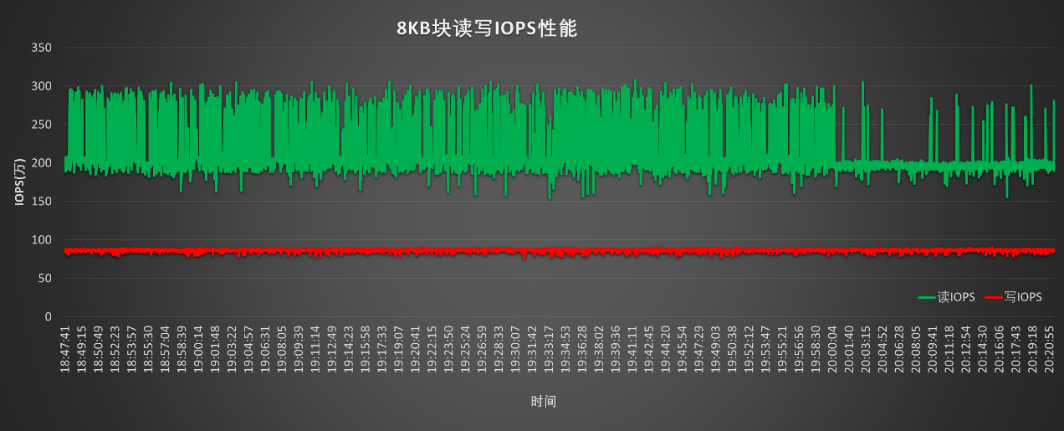
存储容量大,IO读写性能强:可用容量分别为195TB NVMe SSD高性能硬盘存储(10个存储节点)及11PB的普通SATA存储(30个存储节点),采用同一目录命名空间/gpfs,系统自动根据数据访问在高速存储及普通存储池中迁移,确保发挥更大性能。实测性能:
单流读带宽,读≥6GB/s,写≥6GB/s
聚合读写带宽:读≥160GB/s,写≥100GB/s
随机读写IOPS:读≥205万,写≥80万
高计算及IO网络:200Gbps的InfiniBand HDR200高速网络,支持节点间GPU卡间(GPUDirect RDMA)、与存储(GPU Direct Storage-GDS)等的RDMA通信,大大提升了性能。
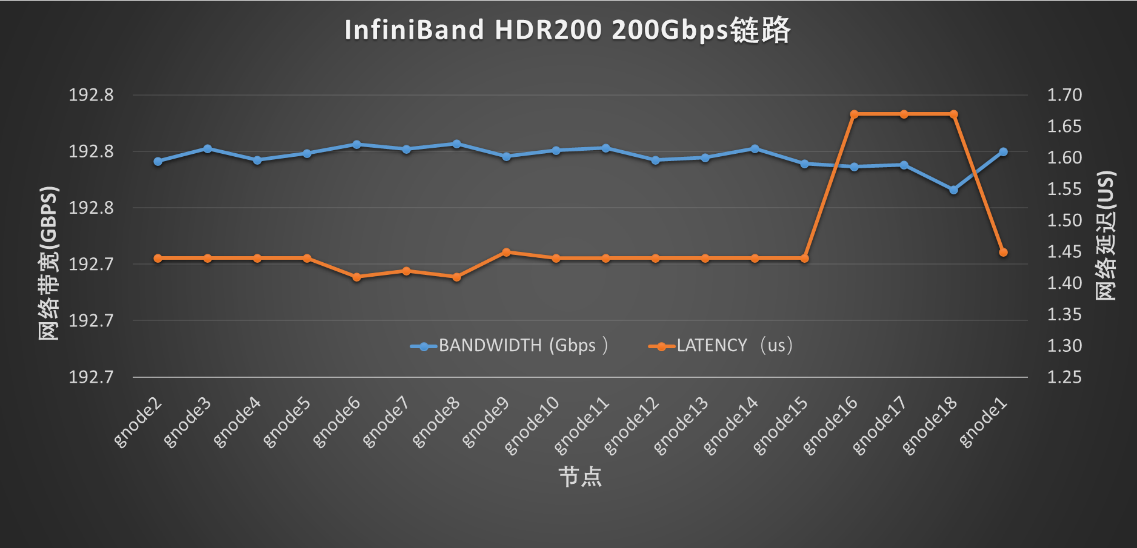
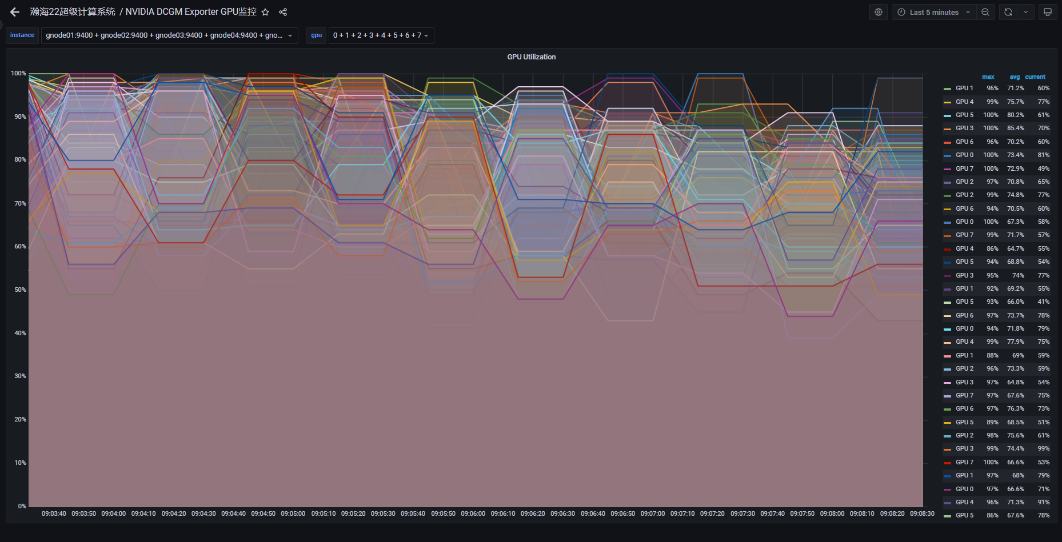
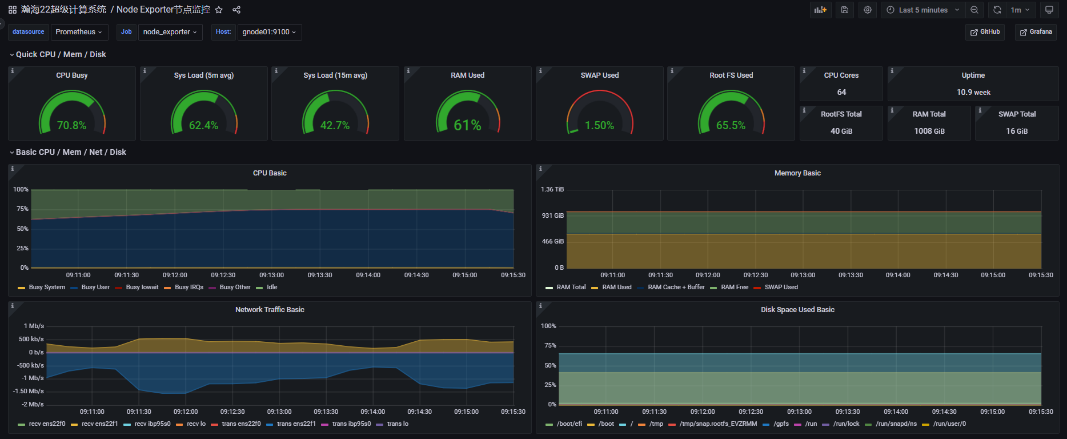
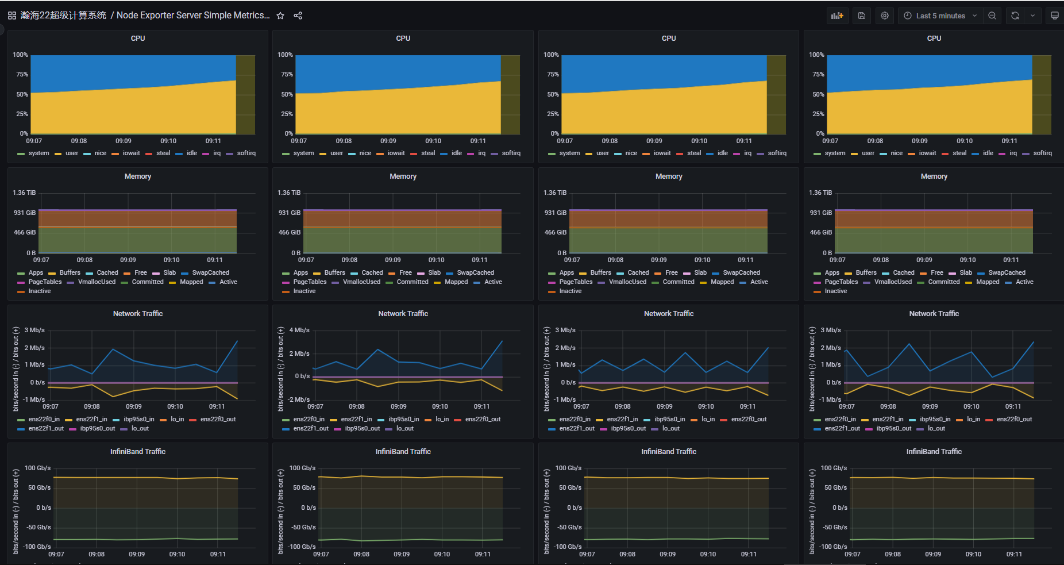
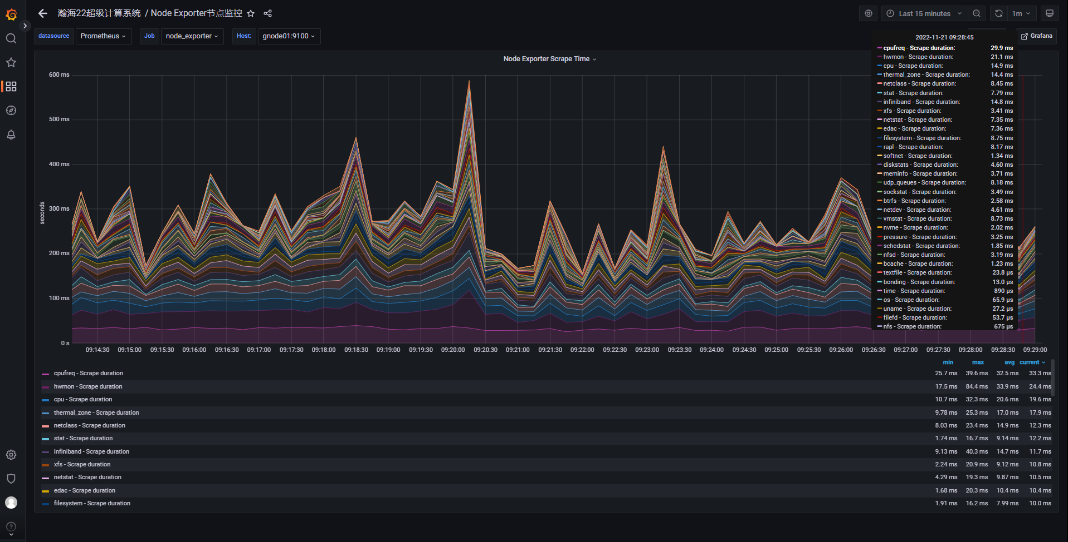
完善的监控系统:实时监控运行情况,优化改进系统等,基于Prometheus、Grafana及自行开发的模块,实现了CPU、GPU、InfiniBand、存储、Slurm作业调度系统等监控。
其他:
用户申请及收费标准:http://scc.ustc.edu.cn/410/list.htm
超算用户QQ群:8355136